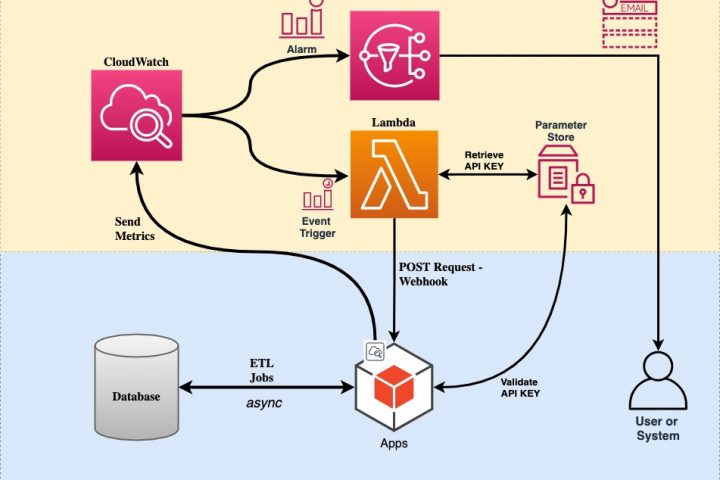
In this article, I explored how machine learning can optimize insurance rider suggestions, with a special shoutout to ChatGPT for making the journey smoother and more enjoyable. Thanks to its assistance, I was able to quickly navigate challenges, refine ideas, and stay entertained throughout the process.