Migration Strategy from Enterprise Scheduling to AWS Hybrid Cloud – Part 2: Implementation
After we have a blueprint for our solutions in part 1, now it is time to implement it into code. We use AWS Cloud Development Kit (CDK) as Infrastructure as a Code and Spring Boot as our custom job implementation.
Overview
In part 1, we talked about requirements, constraints, challenges, and solutions to migrate enterprise scheduler into AWS. Now it is time to continue the implementation and do some coding exercises.
Custom Job Application (CJA)
I deploy our CJA with a REST API as an interface between cloud network and private data center. I use Java and Spring Boot as a programming language and framework.
pom.xml
First, we need to add AWS libraries into our pom.xml.
| <!-- snippet --> | |
| <dependency> | |
| <groupId>com.amazonaws</groupId> | |
| <artifactId>aws-java-sdk-cloudwatch</artifactId> | |
| </dependency> | |
| <dependency> | |
| <groupId>com.amazonaws</groupId> | |
| <artifactId>aws-java-sdk-cloudwatchmetrics</artifactId> | |
| </dependency> | |
| <dependency> | |
| <groupId>com.amazonaws</groupId> | |
| <artifactId>aws-java-sdk-events</artifactId> | |
| </dependency> | |
| <dependency> | |
| <groupId>com.amazonaws</groupId> | |
| <artifactId>aws-java-sdk-ssm</artifactId> | |
| </dependency> |
Other libraries are essentials, such as spring boot libraries andLlombok, but my focus for this article is AWS libraries. See full source code on GitHub repositories. Links are provided at the end of this article.
Long-Running Execution and Synchronized Invocation
As we already mentioned in part 1, a job can take more than 15 minutes to complete its tasks. Meanwhile, lambda only can allow a maximum of 15 minutes before it reaches its timeout. Meanwhile, we called our Job API via HTTP invocations. It means lambda will wait for the request until it gets a response or timeout. On the contrary, lambda does not need to know whether the job failed or not. It is part of the monitoring job. It means, fire and forget approach is expected. Therefore, I will create an asynchronous spring bean to execute the jobs. So lambda will only trigger the job initialization and finish its task.
Also, we know that HTTP can handle multiple requests concurrently. Since our CJA endpoint is HTTP as well, it will cause a problem for the synchronized invocation. For this issue, I will use the ReentrantLock library from JDK to handle the potential overlapping threads.
| // RandomMessageProcessor.java | |
| // snippet code | |
| @Async("asyncExecutor") | |
| public void process(RequestDto requestDto) { | |
| if(reentrantLock.isLocked()) { | |
| logger.info("Another thread is processing the processor!"); | |
| return; | |
| } | |
| reentrantLock.lock(); | |
| Random rand = new Random(); | |
| try { | |
| Thread.sleep(rand.nextInt(2000)); | |
| logger.info("Message is: {}", requestDto); | |
| } catch (InterruptedException e) { | |
| logger.error("InterruptedException", e); | |
| } finally { | |
| reentrantLock.unlock(); | |
| } | |
| } | |
Custom Metrics
Because we want to centralize our alert and monitoring systems, we need to implement custom metrics inside our application. Then we will send back the metrics to the cloud watch.

AWS needs four properties for the metrics. There are namespace, dimension, metric and periods (or duration).
I need two types of metrics, which are job latency and job execution results. I get the latency by substracting end time minus start time. And for job status, if success it returns 1 and 0 otherwise. And because I still follow the SOLID principle, I will create an AOP implementation for metrics collectors.
| // CloudWatchAgentAspect.java -- snippet code | |
| @Around("execution(* com.rurocker.aws.lambdacloudwatch.processor..*(..)))") | |
| public Object sendMetrics(ProceedingJoinPoint proceedingJoinPoint) { | |
| Object result = null; | |
| MethodSignature methodSignature = (MethodSignature) proceedingJoinPoint.getSignature(); | |
| String className = methodSignature.getDeclaringType().getSimpleName(); | |
| Dimension dimension = new Dimension() | |
| .withName("JOB_LATENCY") | |
| .withValue(className); | |
| double status = 1d; | |
| long start = System.currentTimeMillis(); | |
| try { | |
| result = proceedingJoinPoint.proceed(); | |
| } catch (Throwable t) { | |
| logger.error("Error!", t); | |
| status = 0d; | |
| } | |
| long end = System.currentTimeMillis(); | |
| double value = (double) (end - start); | |
| MetricDatum latencyDatum = new MetricDatum() | |
| .withMetricName("JOB_LATENCY") | |
| .withUnit(StandardUnit.Milliseconds) | |
| .withValue(value) | |
| .withDimensions(dimension); | |
| MetricDatum statusDatum = new MetricDatum() | |
| .withMetricName("JOB_STATUS") | |
| .withUnit(StandardUnit.None) | |
| .withValue(status) | |
| .withDimensions(dimension); | |
| PutMetricDataRequest request = new PutMetricDataRequest() | |
| .withNamespace("job-scheduler-poc") | |
| .withMetricData(latencyDatum,statusDatum); | |
| amazonCloudWatch.putMetricData(request); | |
| return result; | |
| } |
API Key
Straightforward implementation. I will retrieve keys from the parameter store then compare them with the current request. If it matches, then continue the request. If it does not, return an unauthorized request to the caller.
| // ParameterRetrieval.java --snippet code | |
| public char[] getApiKey() { | |
| GetParameterRequest parametersRequest = | |
| new GetParameterRequest() | |
| .withName(paremeterStoreKey) | |
| .withWithDecryption(false); | |
| final GetParameterResult parameterResult = | |
| awsSimpleSystemsManagement.getParameter(parametersRequest); | |
| return parameterResult.getParameter().getValue().toCharArray(); | |
| } |
AWS Cloud Development Kit (CDK)
For the AWS Infrastructure, I will use CDK as my infrastructure as a code implementation. Of course, you can use many other tools, such as Terraform. I pick CDK just for the sake of simplicity and familiarity.
You may find lots of permission errors for executing this CDK. You need to patiently add each permission one by one. Of course, the permission problems will solve if you put administrator access to your user. It is not a best practice, but it is easier if you are in a learning phase. BTW, I am not suggesting it :).
VPC
As you may remember, our approach is a hybrid cloud approach. And our CJA lays inside our datacenter. Therefore, we need to deploy our lambda inside our VPC that has a route table to our private network. And this is the first step for CDK Stack.
| # JobTriggerLambdaStack.py | |
| # Get VPC | |
| vpc = Vpc.from_vpc_attributes( | |
| self, | |
| id='vpc-dev', | |
| vpc_id='YOUR_VPC_ID', | |
| availability_zones=core.Fn.get_azs(), | |
| private_subnet_ids=[ | |
| 'YOUR_PRIVATE_SUBNET_ID1', 'YOUR_PRIVATE_SUBNET_ID2', 'YOUR_PRIVATE_SUBNET_ID2'], | |
| private_subnet_route_table_ids=[ | |
| 'YOUR_PRIVATE_ROUTE_TABLE_ID1', 'YOUR_PRIVATE_ROUTE_TABLE_ID2', 'YOUR_PRIVATE_ROUTE_TABLE_ID3'] | |
| ) |
AWS Lambda
First of all, I create the lambda to invoke our CJA. The lambda will retrieve the API Key before sending the request to CJA endpoints. If the response status is 2XX, lambda will consider it as a successful call. Otherwise, lambda will consider as an error.
| import json | |
| import requests | |
| import boto3 | |
| # lambda/testLambdaVPC_CDK.py | |
| def handler(event, context): | |
| client = boto3.client('ssm') | |
| url = 'http://your-server-url:port/aws-poc-notify' | |
| api_key_response = client.get_parameter( | |
| Name='/job-trigger-lambda/api_key', | |
| WithDecryption=False | |
| ) | |
| api_key = api_key_response['Parameter']['Value'] | |
| payload = { | |
| 'id': event['id'], | |
| 'account': event['account'] | |
| } | |
| headers = { | |
| 'Content-Type': 'application/json', | |
| 'API_KEY': api_key, | |
| } | |
| data = json.dumps(payload); | |
| r = requests.post(url=url,data=data,headers=headers) | |
| status_code = r.status_code | |
| if status_code < 200 or status_code > 299: | |
| raise Exception('status_code is {}'.format(status_code)) | |
| return "OK" |
And now we embed the lambda into CDK Stack.
| # JobTriggerLambdaStack.py | |
| # Create lambda | |
| my_lambda = _lambda.Function( | |
| self, 'testLambdaVPC_CDK', | |
| function_name='CDK_test_job_trigger_lambda_vpc', | |
| runtime=_lambda.Runtime.PYTHON_3_7, | |
| code=_lambda.Code.asset('lambda'), | |
| handler='testLambdaVPC_CDK.handler', | |
| vpc=vpc, | |
| log_retention=_logs.RetentionDays.THREE_DAYS, | |
| ) | |
| core.Tags.of(my_lambda).add('src.projectKey', 'job-scheduler-poc') | |
| my_lambda.add_to_role_policy( | |
| _iam.PolicyStatement( | |
| effect=_iam.Effect.ALLOW, | |
| actions=[ | |
| "ssm:Describe*", | |
| "ssm:Get*", | |
| "ssm:List*" | |
| ], | |
| resources=["*"], | |
| ) | |
| ) |
Please note, since we want lambda to retrieve parameter store, we add role to policy in lambda stack.
AWS Simple Notification Service (SNS)
We want to implement an alert and notify us via email. The email notification will be sent by using SNS.
| # JobTriggerLambdaStack.py | |
| # Create SNS | |
| topic = _sns.Topic( | |
| self, | |
| "JobTriggerSNS_POC", | |
| topic_name="CDK_JobTriggerSNS_POC", | |
| ) | |
| core.Tags.of(topic).add('src.projectKey', 'job-scheduler-poc') | |
| topic.add_subscription(_subs.EmailSubscription( | |
| email_address='your-email@xyz.com')) |
AWS SSM Parameter Store
For the API Key, I will store into a parameter store with parameter name /job-trigger-lambda/api_key and random string with 32 characters length.
| # JobTriggerLambdaStack.py | |
| # Create random parameter and store into SSM | |
| _ssm.StringParameter(self, | |
| id="API_KEY", | |
| string_value=''.join(random.choice( | |
| string.ascii_uppercase + string.digits) for _ in range(32)), | |
| parameter_name="/job-trigger-lambda/api_key", | |
| ) |
AWS Cloud Watch Events
Next, I create a CloudWatch Event Rule with a scheduler of one-minute duration as a source and put our lambda as the target.
| # JobTriggerLambdaStack.py | |
| # Create cloudwatch events | |
| rule = _events.Rule( | |
| self, | |
| id='event-trigger', | |
| schedule=_events.Schedule.rate(core.Duration.minutes(1)) | |
| ) | |
| rule.add_target(target=_et.LambdaFunction(my_lambda)) |
Dashboard, Widget, Metrics and Alarm
Now the last stacks are for dashboard, widgets, metrics, and alarm. I use two types of widgets: SingleValueWidget for displaying status and GraphicWidget for displaying latency graphics. The dashboard will display the widgets. And then, I set up the alarm with a specific threshold to determine the status of whether it is okay or in an alarm state.
| # JobTriggerLambdaStack.py | |
| # Dashboard | |
| dashboard = _cw.Dashboard( | |
| self, | |
| id='JobTriggerLambdaDashboard', | |
| dashboard_name='JobTriggerLambdaDashboard', | |
| ) | |
| # Duration Widget | |
| duration_widget = _cw.GraphWidget( | |
| title='Lambda Duration', | |
| width=12, | |
| ) | |
| duration_metrics = _cw.Metric( | |
| namespace='AWS/Lambda', | |
| metric_name='Duration', | |
| dimensions={ | |
| 'FunctionName': my_lambda.function_name | |
| }, | |
| statistic='p99.00', | |
| period=core.Duration.seconds(60), | |
| ) | |
| duration_widget.add_left_metric(duration_metrics) | |
| # and the rest of widgets.. | |
| # add to dashboard | |
| dashboard.add_widgets(duration_widget,stats_widget) | |
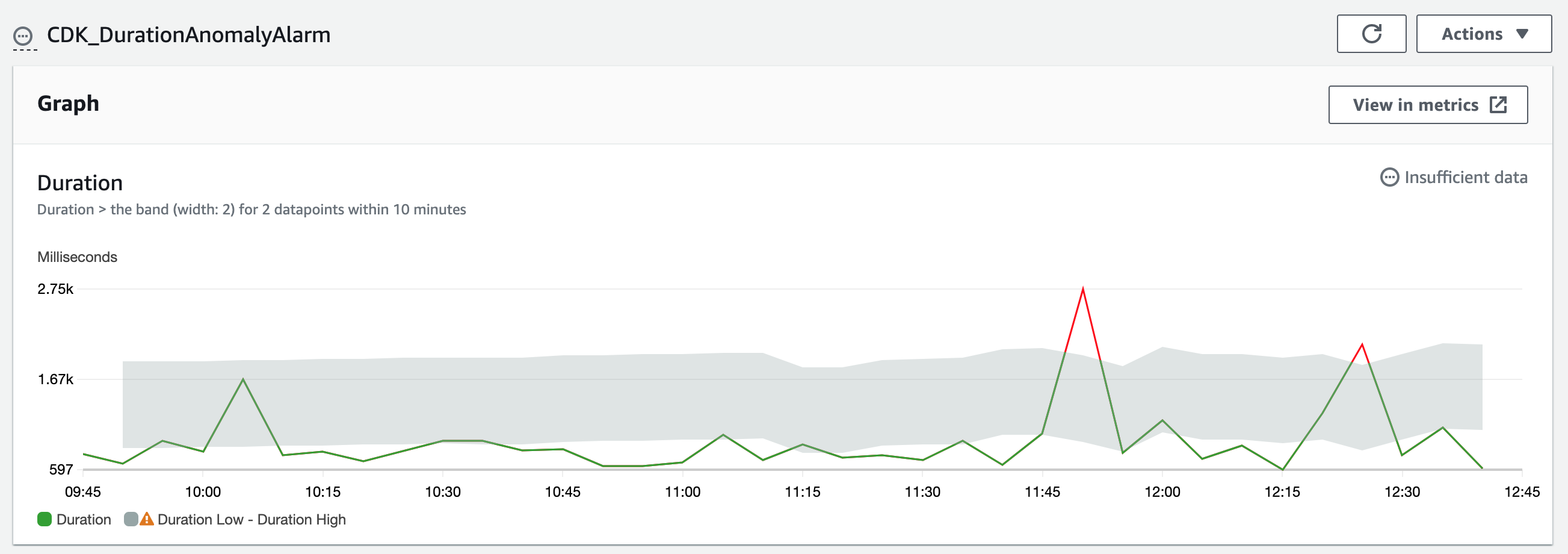
| # alarm: anomaly detection for duration | |
| duration_anomaly_cfnalarm = _cw.CfnAlarm( | |
| self, | |
| "DurationAnomalyAlarm", | |
| actions_enabled=True, | |
| alarm_actions=[topic.topic_arn], | |
| alarm_name="CDK_DurationAnomalyAlarm", | |
| comparison_operator="GreaterThanUpperThreshold", | |
| datapoints_to_alarm=2, | |
| evaluation_periods=2, | |
| metrics=[ | |
| _cw.CfnAlarm.MetricDataQueryProperty( | |
| expression="ANOMALY_DETECTION_BAND(m1, 2)", | |
| id="ad1" | |
| ), | |
| _cw.CfnAlarm.MetricDataQueryProperty( | |
| id="m1", | |
| metric_stat=_cw.CfnAlarm.MetricStatProperty( | |
| metric=_cw.CfnAlarm.MetricProperty( | |
| metric_name='Duration', | |
| namespace='AWS/Lambda', | |
| dimensions=[_cw.CfnAlarm.DimensionProperty( | |
| name='FunctionName', value=my_lambda.function_name)], | |
| ), | |
| period=core.Duration.minutes(5).to_seconds(), | |
| stat="p99.00" | |
| ) | |
| ) | |
| ], | |
| ok_actions=[topic.topic_arn], | |
| threshold_metric_id="ad1", | |
| treat_missing_data="missing", | |
| ) | |
| # and the rest of alarms.. |
After everything is set, it is now to deploy our stacks. After finish deploying our stacks and our CJAs, wait for a while then display the dashboard. You will find something similar with my dashboard:
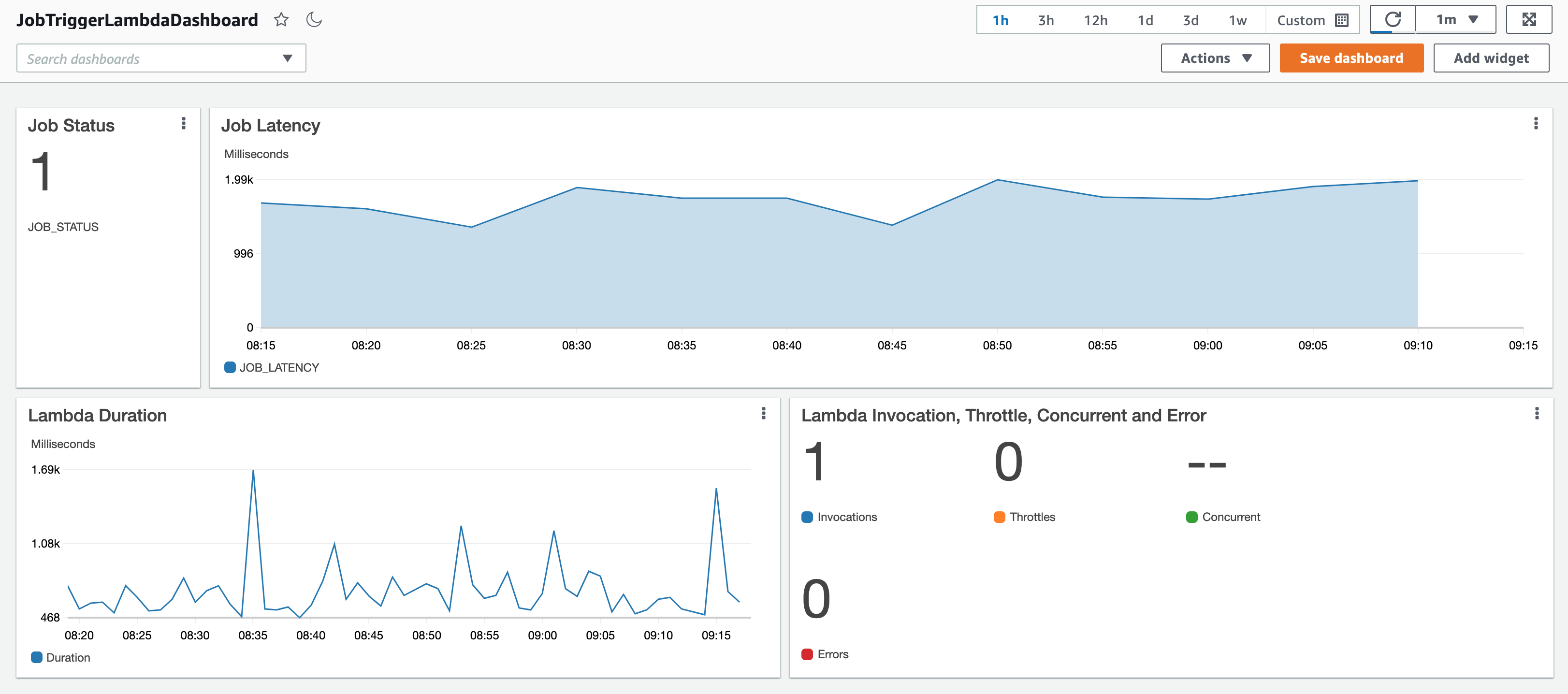
And the alarm state:
Conclusion
By using this approach, we can easily migrate to full cloud native application when the time comes. Just put our CJA into a container and deploy it into Fargate/EKS. However, I know this is possibly not a best solution, and there are plenty of solutions which might work better. If you have a chance to share how you handle this kind of scenario, please do not hesitate to put in comments.
For now, you can check my github:
- CJA https://github.com/ru-rocker/job-trigger-cloud-watch
- CDK https://github.com/ru-rocker/job-trigger-lambda-cdk
One thought on “Migration Strategy from Enterprise Scheduling to AWS Hybrid Cloud – Part 2: Implementation”