Migration Strategy from Enterprise Scheduling to AWS Hybrid Cloud – Part 1: Architecture
Cloud technology is becoming more and more significant in the technology industry. They provide plenty of tools and services, which will enable us to deliver our product faster to the market. On several occasions, migration your infrastructure is not as easy as flipping your palm. We could face lots of challenges; from a business, process, technology, and regulatory perspective.
Overview
Whenever you are working in a regulated industry, such as financial services, you will face a set of rules and compliance before delivering your solutions. There are plenty of regulations and procedures which need to be followed. First, there are government regulations, industry standards and followed by company policies. In the end, they are there to provide the best protection of customer interests.
As an architect or solution provider, sometimes all those things bring unprecedented challenges. We need to design our solution to fit functional as well as non-functional requirements. Functional requirements are pretty straightforward. They are what the user wants. But for the non-functional requirements, it is more a judgment of how the system operates. And one of their categories is a legal category. That relates to how our solution fits with all the regulations.
Requirements and Constraints
For the sake of this article, let say as an architect you have a task to migrate enterprise scheduling system into another solution. The rationale behind the migration is because your company has a limited budget and does not want to extend the license. And because your enterprise scheduler contains some ETL jobs that process customer-sensitive data, your company policy mentions clearly how you need to handle that information. It said that all sensitive data should be resided inside and within the company network.
To make things more complex, your company has invested a lot into cloud technology to reduce cost, as well as software licensing. Therefore, there is a constraint for every solution to be cloud-native ready. At least, when there are some changes in the customer-sensitive data regulations, you can migrate to the cloud with less hassle.
Considerations
With all of those requirements and constraints, we need a combination between cloud and private data centers. Therefore, we expect a hybrid approach for the solution. That will solve the very foundational issue, the home (or data center), and the backbone communication for our solutions.
Now into more detail considerations. There are 5 key points for considerations:
- Scheduler
- Long-running executions
- Synchronized Invocation
- Alert and Monitoring
- Security
Solutions
I will use AWS for the cloud technology and with assumption that the hybrid network has already established.
Scheduler
For scheduler, this is pretty straightforward. We need an interface as a gate for system execution and trigger it periodically. For this case, I will use AWS Cloud Watch Events Rule. The event source will be the Schedule, and the target will be a Lambda function. The lambda function will be responsible invoke our Jobs API in a private data center.
Long-running Execution
Long-running execution is a nature of jobs. It can be minutes to hours for a single job to finish its executions. This nature will cause a problem since we are using lambda as our caller. As you may know, the maximum lambda execution time is 15 minutes. Therefore, we need to make our jobs asynchronous to reduce lambda execution time and evade the timeout.
Synchronized Invocation
Because we make our jobs asynchronous, it will bring another issue to consider. Most of the time, the jobs invocation are synchronous. The current job cannot overlap with the previous one. When there is more than one job replicating source data into output targets, there is a big possibility that your output target will duplicate and can cause havoc on your system behavior.
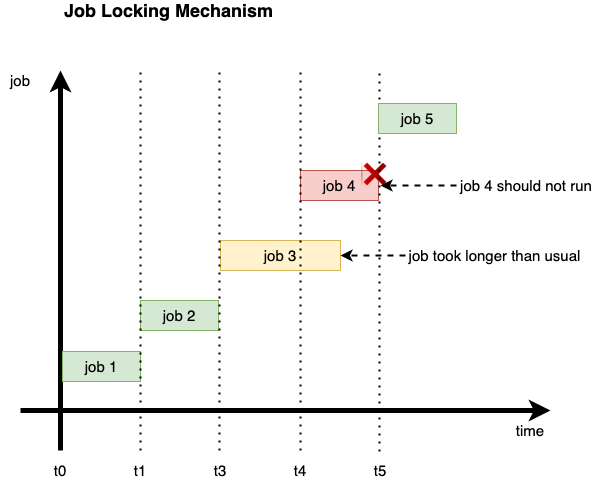
In this picture, let say job-3 has not finished its execution, and the trigger already launches job-4. In this case, we have to terminate job-4 immediately.
Alert and Monitoring
We cannot launch a blind system. We have to know your system behavior, latency, performance, error rate, and many more during the runtime. And on top of all, we need to know alert if something unexpected is going on in your systems. So we can be proactive to reduce the fire before it goes kaboom. Therefore, we will use the Cloud Watch alarm and dashboard as our monitoring tool.
For lambda, it is not a big deal. It has built-in metrics for it. So we can directly use those metrics and display them in our Cloud Watch Dashboard. The problem is our custom jobs in our data center. Of course, we can use different alert and monitoring tools for custom jobs. But it is better to have unification metrics into one single dashboard as well as the alarm configurations. For this purpose, we will use custom AWS metrics in our jobs and export them to Cloud Watch after each execution. Then we will have no issue with displaying the metrics into our dashboard.
Security
Whenever we expose an API, we need to make sure only allowable parties can execute the API. For this case, we only allow requests with a specific API key to launch the jobs. Since this is the key, we will store it into AWS SSM Parameter Store and access it during the runtime. Therefore, no hard-coded API on our code.
Solution Diagram
After all the considerations, let’s put our solutions into one single solution diagram.
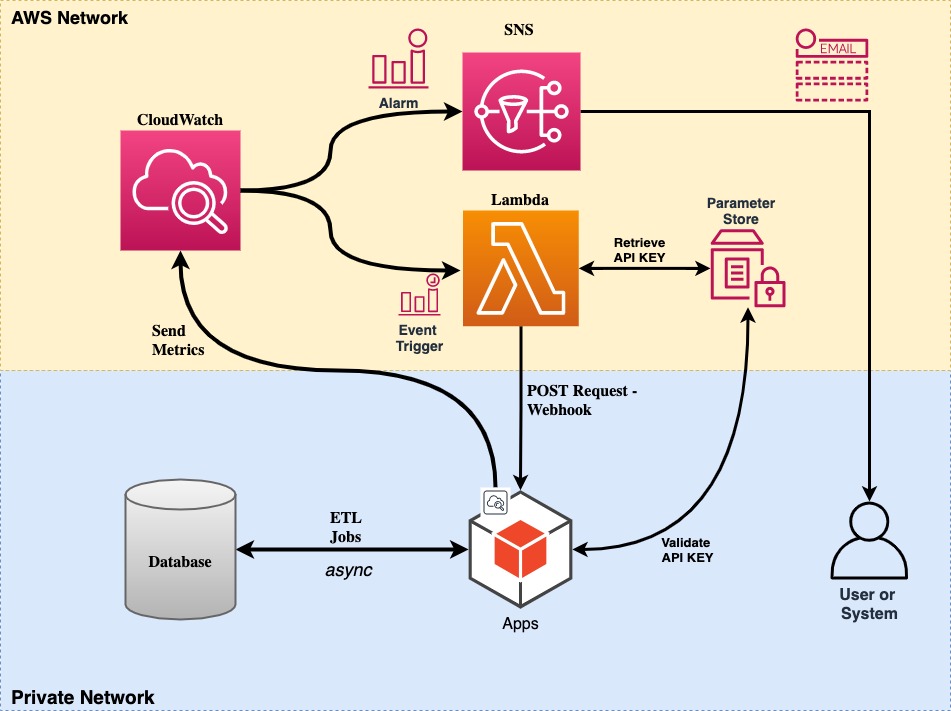
To Be Continue
If you have already got the idea, you may stop here. But if you want to know more about technical detail and implementation of the solutions, please visit part 2.
One thought on “Migration Strategy from Enterprise Scheduling to AWS Hybrid Cloud – Part 1: Architecture”