How to Join One-to-Many and Many-to-One Relationship with Kafka Streams
Yet another Kafka feature, which is Kafka Streams, allow us to join two streams into one single stream. Kafka streams provide one-to-many and many-to-one join types.
Overview
In this article, I once again will bring Kafka as my use case. I talked a lot about securing Kafka in my last three blog posts. So, today is going to be a little bit different. I will talk about another feature of Kafka, which is Kafka Streams.
Kafka Streams
Well, if you expect me to discuss transformation operations, such as map, flatmap, and filter; they are not my main today’s focus. What I want to discuss is another feature of Kafka Stream, which is joining streams. More specifically, I will conduct two types of join, in a similar pattern of an RDBMS world. They are one-to-many (1:N) and many-to-one (N:1) relations.
Of course, while preparing streams before joining, I will need some transformation, such as re-key, group by, and aggregate partition. However, the essential factor today is to join the stream itself.
All the join semantics, such as left join, inner join, outer join and their behavior are beyond the scope of this article. This article is solely focused on KTable inner join. There is a slight difference, especially for the KStream-to-KStream join type. Please visit this link for more details.
Use Case
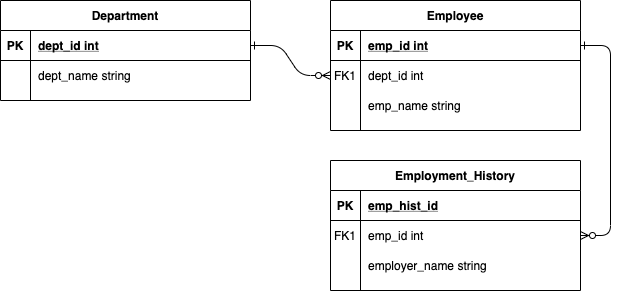
Let say I have three sources of employee data. They are Department, Employee, and Employment History. Each employee belongs to one department, and he/she can have multiple employment history. Our goal is to simplify those sources of data into one single employee representation.
Entity-Relationship Diagram
I translate the use case into a more familiar Entity-Relationship Diagram.
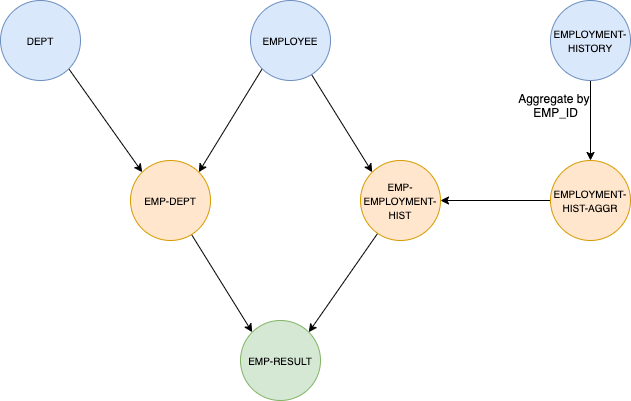
Topology
Here is the topology. The blue color is for input topics and their aggregation. The orange one is for Kafka’s internal topic and/or materialized view. And the green one is for the output topic.
Kafka Topics
Therefore, for the demo purpose, I created 4 Kafka topics. They are DEPT, EMPLOYEE, EMPLOYMENT-HISTORY, and EMP-RESULT. The first three are input topics. And the last one is an output topic.
|
1 2 3 4 5 |
# Create kafka topics kafka-topics --zookeeper localhost:2181 --topic DEPT --create --replication-factor 1 --partitions 1 kafka-topics --zookeeper localhost:2181 --topic EMPLOYEE --create --replication-factor 1 --partitions 1 kafka-topics --zookeeper localhost:2181 --topic EMPLOYMENT-HISTORY --create --replication-factor 1 --partitions 1 kafka-topics --zookeeper localhost:2181 --topic EMP-RESULT --create --replication-factor 1 --partitions 1 |
Sample Data
Here are the sample data for this demo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# DEPT {"dept_id":1,"dept_name":"HR"} {"dept_id":2,"dept_name":"IT"} # EMPLOYEE {"emp_id":1,"dept_id":1,"emp_name":"Alice"} {"emp_id":2,"dept_id":"1","emp_name":"Bob"} {"emp_id":3,"dept_id":2,"emp_name":"Charlie"} # EMPLOYMENT HISTORY {"emp_hist_id":1,"emp_id":3,"employer_name":"ABC"} {"emp_hist_id":2,"emp_id":3,"employer_name":"DEF"} {"emp_hist_id":3,"emp_id":1,"employer_name":"XYZ"} {"emp_hist_id":4,"emp_id":2,"employer_name":"FOO"} |
Step-by-Step
JSON (De)Serializer, POJO and Serdes
First, I need to prepare serializer and deserializer for parsing JSON object into POJO. Then, I created five DTOs. Three DTOs for source data, which are EmployeeDto, DepartmentDto, and EmploymentHistoryDto. Next, to handle Employement History aggregation, I need EmploymentHistoryAggregationDto. The last one is EmployeeResultDto; to handle the final streams join result. Lastly, I created Serdes for each DTO.
Many-to-One Relationship: Department and Employee (N:1)
Because all our sample data has no Kafka topic key, therefore at first, we need to select our key first before converting it into
KTable.
Department Topology
|
1 2 3 4 5 6 7 8 9 |
// select key then convert stream into table final KTable<Integer, DepartmentDto> deptTable = builder.stream("DEPT", Consumed.with(Serdes.Integer(), MySerdesFactory.departmentSerde())) .map((key, value) -> new KeyValue<>(value.getDeptId(), value)) .toTable(Materialized.<Integer, DepartmentDto, KeyValueStore<Bytes, byte[]>> as("DEPT-MV") .withKeySerde(Serdes.Integer()) .withValueSerde(MySerdesFactory.departmentSerde())); |
Employee Topology
|
1 2 3 4 5 6 7 8 9 |
// select key then convert stream into table final KTable<Integer, EmployeeDto> empTable = builder.stream("EMPLOYEE", Consumed.with(Serdes.Integer(), MySerdesFactory.employeeSerde())) .map((key, value) -> new KeyValue<>(value.getEmpId(), value)) .toTable(Materialized.<Integer, EmployeeDto, KeyValueStore<Bytes, byte[]>> as("EMPLOYEE-MV") .withKeySerde(Serdes.Integer()) .withValueSerde(MySerdesFactory.employeeSerde())); |
Department-Employee Join Topology
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
// N:1 join -> EMPLOYEE and DEPARTMENT final KTable<Integer, EmployeeResultDto> empDeptTable = empTable.join(deptTable, // foreignKeyExtractor. Get dept_id from employee and join with dept EmployeeDto::getDeptId, // join emp and dept, return EmployeeResultDto (emp, dept) -> { EmployeeResultDto employeeResultDto = new EmployeeResultDto(); employeeResultDto.setDeptId(dept.getDeptId()); employeeResultDto.setDeptName(dept.getDeptName()); employeeResultDto.setEmpId(emp.getEmpId()); employeeResultDto.setEmpName(emp.getEmpName()); return employeeResultDto; }, // store into materialized view with neam EMP-DEPT-MV Materialized.<Integer, EmployeeResultDto, KeyValueStore<Bytes, byte[]>> as("EMP-DEPT-MV") .withKeySerde(Serdes.Integer()) .withValueSerde(MySerdesFactory.employeeResultSerde()) ); |
One-to-Many Relationship: Employee and Employment History
We already have a KTable, which is a result of a joined stream between Department-Employee. Hence we will join this with the Employment History stream.
Employment History Topology
Employment History has its unique key, which is emp_hist_id. However, we need this set of data in an emp_id perspective. Therefore, we need to pivot the data by selecting emp_id as a key. Then we need to do some data aggregations since there are multiple records within the same emp_id.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// a. select emp_id as key, group by key (emp_id) then aggregate the result final KTable<Integer, EmploymentHistoryAggregationDto> employmentHistoryAggr = builder.stream("EMPLOYMENT-HISTORY", Consumed.with(Serdes.Integer(), MySerdesFactory.employeeHistorySerde())) .selectKey((key,empHist) -> empHist.getEmpId()) .groupByKey(Grouped.with(Serdes.Integer(), MySerdesFactory.employeeHistorySerde())) .aggregate( // Initialized Aggregator EmploymentHistoryAggregationDto::new, //Aggregate (empId, empHist, empHistAggr) -> { empHistAggr.setEmpId(empId); empHistAggr.add(empHist.getEmployerName()); return empHistAggr; }, // store in materialied view EMPLOYMENT-HIST-AGGR-MV Materialized.<Integer, EmploymentHistoryAggregationDto, KeyValueStore<Bytes, byte[]>> as("EMPLOYMENT-HIST-AGGR-MV") .withKeySerde(Serdes.Integer()) .withValueSerde(MySerdesFactory.employmentHistoryAggregationSerde()) ); |
Employee-EmploymentHistory Join Topology
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
// b. join with EMP-DEPT. Since the key is already identical, which is EMP_ID, no need FK Extractor final KTable<Integer, EmployeeResultDto> empResultTable = empDeptTable.join(employmentHistoryAggr, // Value Joiner (empResult, histAggr) -> { empResult.setEmploymentHistory(histAggr.getEmploymentHistory()); return empResult; }, // store in materialied view EMP-RESULT-MV Materialized.<Integer, EmployeeResultDto, KeyValueStore<Bytes, byte[]>> as("EMP-RESULT-MV") .withKeySerde(Serdes.Integer()) .withValueSerde(MySerdesFactory.employeeResultSerde()) ); |
Output Topic
Stream Joined Result to Output Topic
Before we send the result into the output topic, we select emp_id as a topic’s key and EmployeeResultDto as a topic’s value.
|
1 2 3 4 5 6 |
// store result to output topic EMP-RESULT empResultTable.toStream() .map((key, value) -> new KeyValue<>(value.getEmpId(), value)) .peek((key,value) -> System.out.println("(empResultTable) key,value = " + key + "," + value)) .to("EMP-RESULT", Produced.with(Serdes.Integer(), MySerdesFactory.employeeResultSerde())); } |
Sample Result
|
1 2 3 4 5 6 7 8 9 10 |
{ "emp_id": 3, "dept_id": 2, "emp_name": "Charlie", "dept_name": "IT", "employment_history": [ "ABC", "DEF" ] } |
Future Enhancement
Whenever we are looking at employee output data, it will trigger an enterprise integration pattern inside our minds. Any idea what pattern it is? To answer the question, let us look at all those previous steps so far.
First, we acquired data from multiple streams. Then we identified their correlation. Next, we publish them into a single, aggregated messages to the output channel. Truthfully, at the very basic, it is an aggregator pattern.
Moreover, we can enhance further regarding this aggregation into CQRS architecture. To put things in context, imagine our source of data is multiple command requests. We stream the data from Kafka topics and sink (Kafka Connect anyone?) the result into another DB that specifically optimized for search. Let say we are using ElasticSearch for querying our aggregated data. Thus we split the READ operation with WRITE operation.
One more interesting fact, whether you realize or not, we already defined a boundary itself, which is Employee Domain. I realized that I am oversimplifying the domain itself. However, my point is, there is a possibility to implement Domain-Driven Design by using Kafka Streams as a groundwork.
Yet it is another topic and already out of scope this blog post. At least, we have already had the foundation grip to go further. For now, enjoy the code in my github repository.
References
- https://kafka.apache.org/20/documentation/streams/developer-guide/dsl-api.html
- https://www.enterpriseintegrationpatterns.com/patterns/messaging/Aggregator.html
Great article. This is one of the best I have seen so far, which put thoughts into more realistic example than some random thoughts. Great work keep it up :>
Thank you. Glad to help 😉
Thanks for the great article. How do we handle late arrival records in join operation?
in the above join operation, we will get the duplicate records in the topic.
Say for example, if one employee has 4 history record. In the output topic, we will have the records like
1. employee with 1st history record.
2, employee with first two history records
3. employee with first three history records
4. employe with all the history records.
In this case, only the last record is correct record. How do we restrict the duplicate records?
Please share your input.
Yes. The order would be just as you mentioned because it is a changelog stream.
In the end, you will get the correct results.
As you may know, your case is an example of an event-driven system.
Therefore, eventual consistency is a common thing to happen in this kind of situation. Or let say, based on the CAP theorem, it is a trade-off when we choose this kind of approach in distributed systems.
Further references:
https://docs.confluent.io/current/streams/concepts.html#ktable
You will not get duplicate records, because the approach is to aggregate the employment history. What you need to do, only “update” your target data, with the latest employee record (which already has all the history records), based on its key (EMP_ID).
Thank you for this article. This is helped me a lot.
1. I am trying to write the employeeResult to a file but its not writing when application is running. I need to stop my java server to see the result in file – result.txt
empResultTable.toStream()
.map((key, value) -> new KeyValue(value.getEmpId(), value))
.print(Printed.toFile(“resul.txt”));
2. How can I achieve the same with KStream-KStream join (foreign key)
Thank you!
Geeta
Thank you for this article. This has helped me a lot. Can you help in resolving the following issues:
1. I am trying to write the employeeResult to a file but its not writing when application is running. I need to stop my java server to see the result in file – result.txt
empResultTable.toStream()
.map((key, value) -> new KeyValue(value.getEmpId(), value))
.print(Printed.toFile(“resul.txt”));
2. How can I achieve the same with KStream-KStream join (foreign key)
Thank you!
Geeta
I never print to a file from a stream. So I cannot say much about this. But maybe, just maybe, it is because the streams keep your file open in order to write the payload. You need to close the file first to create the file into filesystem. That’s why if you keep your streams running, it will not create a file and it is created once you terminated the streams. Maybe you can check on this more to validate my assumptions.
And for the KStream-KStream join, you can achieve similarly with KTable. A slight difference is you need to mention the join windows.
I created another article related KStream-KStream join. See the sample here: https://www.ru-rocker.com/2021/01/03/a-study-case-building-a-simple-credit-card-fraud-detection-system-part-2-mapping-gerkhin-to-kafka-streams/
Thank you for the response.
I tried as shown below but its not working. Could you please suggest
public class EmployeeTopology {
public void createTopology(StreamsBuilder builder) {
final KStream empStream =
builder.stream(“EMPLOYEE”,
Consumed.with(Serdes.Integer(), MySerdesFactory.employeeSerde()))
.map((key, value) -> new KeyValue(value.getEmpId(), value));
final KStream deptStream =
builder.stream(“DEPT”,
Consumed.with(Serdes.Integer(), MySerdesFactory.departmentSerde()))
.map((key, value) -> new KeyValue(value.getDeptId(), value));
KStream resultStream =
deptStream.join(empStream,
valueJoiner(),
JoinWindows.of(Duration.ofSeconds(1)),
StreamJoined.with(
Serdes.Integer(),
MySerdesFactory.departmentSerde(),
MySerdesFactory.employeeSerde()));
resultStream.print(Printed.toSysOut());
}
private ValueJoiner valueJoiner() {
return (dept, emp) -> {
if (dept.getDeptId() == emp.getDeptId()) {
EmployeeResultDto dto = new EmployeeResultDto();
dto.setDeptId(emp.getEmpId());
dto.setEmpName(emp.getEmpName());
dto.setDeptName(dept.getDeptName());
return dto;
}else{
return null;
}
};
}
}
KStream-KStream join is working. my bad I had provided – window of 5 seconds.
2. about writing to file
empResultTable.toStream()
.map((key, value) -> new KeyValue(value.getEmpId(), value))
.print(Printed.toFile(“resul.txt”));
I didn’t find the way to close this file as Printed.toFile expects file path.
Thank you for all the support
I am trying to join 2 kstreams using hopping window but join accepts only JoinWindows not the TimeWindows. how can I achieve this?
I think it is because its design.
From the website: https://kafka.apache.org/20/documentation/streams/developer-guide/dsl-api.html#kstream-kstream-join
“KStream-KStream joins are always windowed joins, because otherwise the size of the internal state store used to perform the join – e.g., a sliding window or “buffer” – would grow indefinitely.”
While running the application I am getting below error :
C:\Users\UJ54KD\Softwares\openjdk-11+28_windows-x64_bin\jdk-11\bin\java.exe “-javaagent:C:\Users\UJ54KD\AppData\Local\JetBrains\IntelliJ IDEA Community Edition 2022.2.2\lib\idea_rt.jar=54099:C:\Users\UJ54KD\AppData\Local\JetBrains\IntelliJ IDEA Community Edition 2022.2.2\bin” -Dfile.encoding=UTF-8 -classpath C:\Users\UJ54KD\Workspaces\KafkaStreamEmployee\target\classes;C:\Users\UJ54KD\.m2\repository\org\apache\kafka\kafka-streams\2.5.0\kafka-streams-2.5.0.jar;C:\Users\UJ54KD\.m2\repository\org\apache\kafka\connect-json\2.5.0\connect-json-2.5.0.jar;C:\Users\UJ54KD\.m2\repository\org\apache\kafka\connect-api\2.5.0\connect-api-2.5.0.jar;C:\Users\UJ54KD\.m2\repository\org\slf4j\slf4j-api\1.7.30\slf4j-api-1.7.30.jar;C:\Users\UJ54KD\.m2\repository\org\rocksdb\rocksdbjni\5.18.3\rocksdbjni-5.18.3.jar;C:\Users\UJ54KD\.m2\repository\org\apache\kafka\kafka-clients\2.5.0\kafka-clients-2.5.0.jar;C:\Users\UJ54KD\.m2\repository\com\github\luben\zstd-jni\1.4.4-7\zstd-jni-1.4.4-7.jar;C:\Users\UJ54KD\.m2\repository\org\lz4\lz4-java\1.7.1\lz4-java-1.7.1.jar;C:\Users\UJ54KD\.m2\repository\org\xerial\snappy\snappy-java\1.1.7.3\snappy-java-1.1.7.3.jar;C:\Users\UJ54KD\.m2\repository\org\apache\commons\commons-lang3\3.10\commons-lang3-3.10.jar;C:\Users\UJ54KD\.m2\repository\commons-io\commons-io\2.6\commons-io-2.6.jar;C:\Users\UJ54KD\.m2\repository\com\fasterxml\jackson\module\jackson-module-parameter-names\2.11.0\jackson-module-parameter-names-2.11.0.jar;C:\Users\UJ54KD\.m2\repository\com\fasterxml\jackson\core\jackson-core\2.11.0\jackson-core-2.11.0.jar;C:\Users\UJ54KD\.m2\repository\com\fasterxml\jackson\core\jackson-databind\2.11.0\jackson-databind-2.11.0.jar;C:\Users\UJ54KD\.m2\repository\com\fasterxml\jackson\datatype\jackson-datatype-jdk8\2.11.0\jackson-datatype-jdk8-2.11.0.jar;C:\Users\UJ54KD\.m2\repository\com\fasterxml\jackson\datatype\jackson-datatype-jsr310\2.11.0\jackson-datatype-jsr310-2.11.0.jar;C:\Users\UJ54KD\.m2\repository\com\fasterxml\jackson\core\jackson-annotations\2.11.0\jackson-annotations-2.11.0.jar;C:\Users\UJ54KD\.m2\repository\net\logstash\logback\logstash-logback-encoder\5.3\logstash-logback-encoder-5.3.jar org.example.Main
SLF4J: Failed to load class “org.slf4j.impl.StaticLoggerBinder”.
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
Exception in thread “KafkaStream-TopologyPOC-bede1894-9af6-4ebd-974b-19a58937c9ca-StreamThread-1” org.apache.kafka.streams.errors.StreamsException: Deserialization exception handler is set to fail upon a deserialization error. If you would rather have the streaming pipeline continue after a deserialization error, please set the default.deserialization.exception.handler appropriately.
at org.apache.kafka.streams.processor.internals.RecordDeserializer.deserialize(RecordDeserializer.java:80)
at org.apache.kafka.streams.processor.internals.RecordQueue.updateHead(RecordQueue.java:175)
at org.apache.kafka.streams.processor.internals.RecordQueue.addRawRecords(RecordQueue.java:112)
at org.apache.kafka.streams.processor.internals.PartitionGroup.addRawRecords(PartitionGroup.java:162)
at org.apache.kafka.streams.processor.internals.StreamTask.addRecords(StreamTask.java:765)
at org.apache.kafka.streams.processor.internals.StreamThread.addRecordsToTasks(StreamThread.java:943)
at org.apache.kafka.streams.processor.internals.StreamThread.runOnce(StreamThread.java:764)
at org.apache.kafka.streams.processor.internals.StreamThread.runLoop(StreamThread.java:697)
at org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:670)
Caused by: org.apache.kafka.common.errors.SerializationException: Size of data received by IntegerDeserializer is not 4