A Food for Thought: How to Share Data Among Services in a Microservice World (part 1)
A microservice architecture is all about transferring data from one service to another.
Overview
In the world of microservice architecture, it is an inevitable need to share data among services. Even more, the demands of intercommunicating services are a common practice. In my experience, I never find any solitude service that never shares any of its data with others. There are many ways to initiate communications between services. Whether they are using database sharing, HTTP request communications, or messaging/streams. As always, there is no silver bullet for this problem. Therefore in today’s article, I will try to explore some data sharing alternatives with some examples.
Use Case
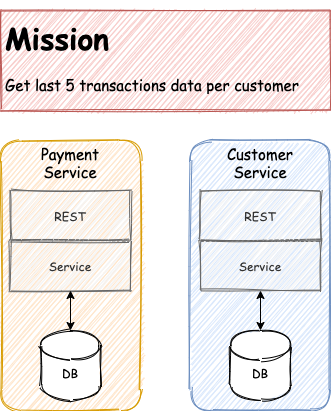
Let say we have two services, which are Payment Service (PS) and Customer Service (CS). Our mission is to display the last five transactions from Payment Service on Customer Service.
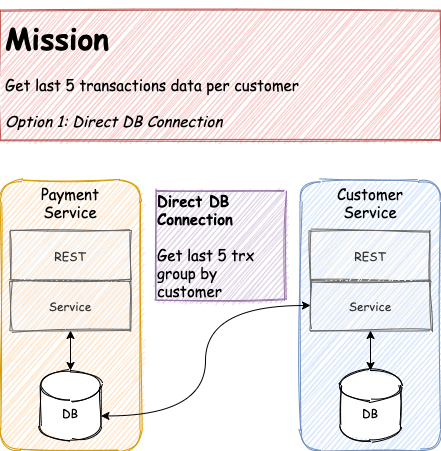
Direct Database Connection
This is probably the easiest and simplest implementation mechanism. All you need is to setup the database connection from CS to Payment DB.
Easy to Implement
Even though it is the fastest solution you can achieve, I would NOT encourage this solution. Why did I say that? Well, unless you have a dragon breathing on your neck and ready to spit fire anytime soon, this solution will bring more problems in the near future rather than a smart solution.
Single Point of Failure
Now you have two services that are tightly coupled to a single database instance. So whenever there are some outages in Payment DB, there is a big possibility that PS and CS will experience service downtime as well.
You can always argue that your databases are already redundant and their setup already support high availability. Yes, it reduces the chance for downtime experiences. But how about altering some payment tables that will impact CS?
Hint: you still need to change queries and release database connection (shutdown) to alter payment tables. Also, you need to consider the amount of coordination efforts and re-prioritization backlog between these two services to deploy the changes.
Transparency and Scalability
Another issue with the direct database connection approach is transparency. First, you need to know the exact location where the database is located, whether it is in the form of an IP Address or DNS. And then you have to have the specific programming language database driver with a suitable version. As a result, this will bring another burden for you, in terms of service maintenance.
Also, the database is not a really good fit for scalability. You can scale out, vertically and/or horizontally, but it usually does not come with a cheap price.
HTTP Call
This option is more likely to happen rather than the previous one. This form of communication is easy to understand and we have been using HTTP call around since the era of internet booming (or HTTP/1.1 adoption).
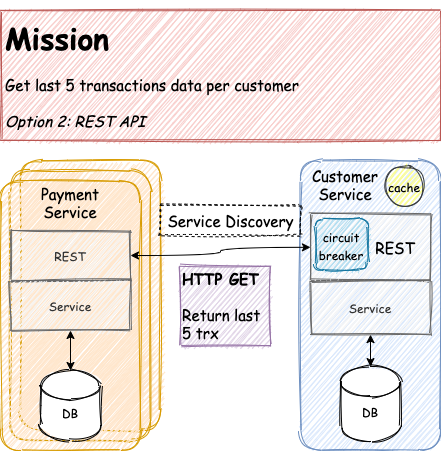
Easy to Implement and Plenty of Technology Options
As stated previously, we have been playing around with HTTP protocol for some amount of times (even years). Therefore, there are almost no mountain challenges to implement this method.
There are plenty of open-source libraries on the internet to make your life easier when dealing with the nature of synchronous HTTP calls. Such as Netflix, they share their library to public consumption. For instance, Eureka for service discovery, Feign for declarative HTTP call as well as load-balancer and Hystrix as a circuit breaker.
Scalability is not an issue as well with this approach. It just a matter of spinning up another pod or container whenever there is a spike in requests. And as easy as scaling down again whenever the request is back to normal.
Business Scenario Challenges
Everything looks in good shape so far. I have to admit, this approach is pretty stable for medium to long term approach, until the unprecedented is coming and knocking our door.
Let say, our Payment Service initially only serves credit card payments. However, due to business expansion, we started to acquire more channels and established cooperation with bank. Thus, we now have to setup a new bank transfer channel.
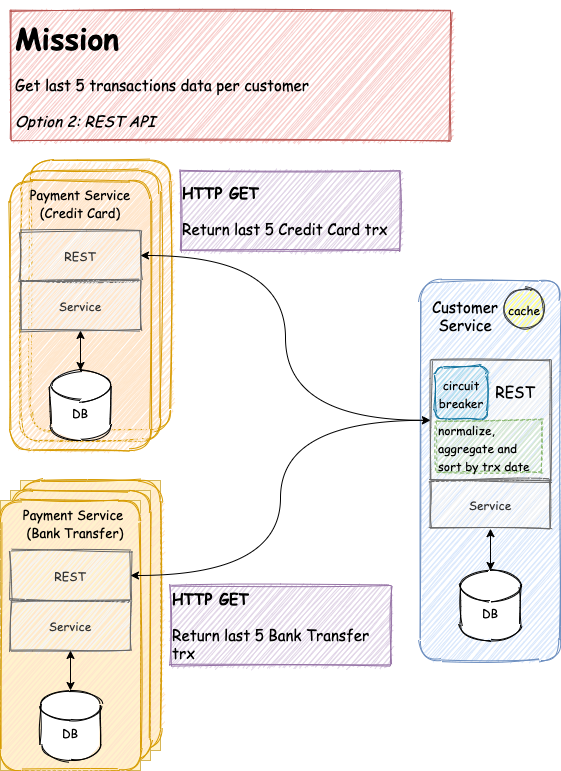
Now we are facing a new level of complexity. As an assumption, we consider the payload between the two payment services is different. Credit Card Payment Service‘s payload is JSON, meanwhile for Bank Transfer Payment Service‘s payload is XML. As a consequence, on the CS side, we have an additional task to implement.
Different Payload
First, we need to normalize the two different payloads into a single and acceptable one. Then we need to merge them, aggregate, sort, and retrieve their last five transactions. Well, it is easy when you only have to retrieve only from two services. How about retrieve payment information for, let say, 10 to 20 services? How many computations do you need to do on the CS side?
Another issue that will arise is latency. Because of the nature of HTTP synchronicity, Customer Service only returns the last five transactions data as long as the slowest HTTP connection between services, or when a timeout occurs. Timeout itself does not solve any problem. Instead, it adds another problem.
Timeout
Let say our Bank Transfer Payment Service contains the last transaction data. In the first attempt, our customer managed to successfully retrieve data from both services. Then he refreshed the same page, and suddenly Bank Transfer Payment Service experienced timeout. Because we combine the result of both services, now the result is only his last five transactions from credit card payment. It will bring inconsistent results to our customers, and in the end, it will impact customer distrust with our system.
Another technique to handle this problem is by polling each Payment Service in a specific duration. Let say we poll them every 30 minutes. Then we store the result into a database. However, this will raise another issue, which is a network. You will over flooding the network for retrieving probably the same data every 30 minutes. And factor it with the number of customers. Either your service or your network will eventually be slowing down with this approach.
The borderline is, even though the HTTP interface looks pretty simple, it does not move the data around.
To Be Continue..
I will discuss about the third option, which is the messaging or stream in the part 2.
One thought on “A Food for Thought: How to Share Data Among Services in a Microservice World (part 1)”